
Artificial intelligence and large language models are no longer confined to innovation labs.
They have quietly moved into the control room.
In 2025–2026, the most consequential decisions in banking, payments, wealth management, consumer finance, and enterprise financial operations are increasingly shaped, and often determined, by AI systems.
Credit limit increases. Real-time transaction approvals or blocks. Fraud alerts that trigger account freezes. Sanctions screening hits. KYC/CDD accept-or-decline decisions. Customer service resolutions involving refunds or fee waivers. Personalized investment recommendations. Algorithmic order routing. Internal workflow routing and exception handling.
These are no longer supporting analytics.
They are operational decision engines.
And once a system becomes the decision-maker rather than a decision-support tool, the risk equation changes completely.
The Old Playbook No Longer Works
Most organizations still approach AI security using the same mental model applied to traditional IT systems:
Prevent unauthorized access
Patch vulnerabilities
Monitor for anomalous network behavior.
Detect credential abuse
Block malware execution
All valid controls. All necessary.
But almost none detect the failure modes now driving nine-figure losses, multi-year regulatory actions, public brand crises, and even criminal facilitation.
Why?
Because the dominant attack surface has shifted.
Attackers no longer need to:
Exploit an application vulnerability.
Steal an API key
Perform lateral movement
Deploy ransomware
Break encryption
They simply need to mislead the model itself or exploit how authority has been delegated to it.
When they succeed, the logs usually look normal.
Welcome to the Era of “No-Hack” AI Incidents
The pattern is now painfully consistent across jurisdictions and institution types:
Deepfake executive impersonation → multi-million unauthorized transfers (no malware, no stolen credentials — just logic that trusted synthetic identity signals)
Synthetic identity factories → systematic onboarding bypass (no infrastructure breach — just generative models beating liveness and document checks)
Prompt-engineered refund abuse → thousands of unauthorized credits (no session hijacking — just conversation chaining that disabled guardrails)
Agent over-permissioning → internal data exfiltration via “helpful assistant” behavior (no privilege escalation — just overly permissive tool access)
Behavioral mimicry → AML evasion at scale (no signature-based detection — just adaptive behavior below thresholds)
In every case, the root cause was not a missing firewall rule or an unpatched library.
The root cause was untested, over-trusted AI decision logic.
Critically, traditional red-team exercises, penetration tests, and vulnerability scans rarely uncover these issues — because they are not looking in the right place.
The Attack Surface Has Shifted Away from Infrastructure
Most security programs remain oriented around infrastructure-centric threats: unauthorized access, software vulnerabilities, malware, credential abuse, lateral movement, and data exfiltration.
These controls still matter.
They are no longer sufficient.
The most damaging AI-related failures in financial services today do not involve infrastructure compromise. They involve logic abuse, where AI systems behave incorrectly while operating as designed.
In these scenarios:
APIs are invoked correctly.
Authentication succeeds
Logs show valid activity.
No malware is present.
No indicators of compromise exist.
Only the decision outcome is wrong.
Prompt Injection and Jailbreaking Attacks

Prompt injection remains the most prevalent and reliable attack technique against AI systems.
Attackers embed hidden instructions within seemingly legitimate inputs such as customer messages, uploaded documents, structured forms, PDFs, or images processed via OCR. Over repeated interactions, the model’s behavior is gradually reshaped. The AI begins to follow the attacker-supplied instructions rather than organizational rules.
This does not require bypassing authentication or exploiting a vulnerability. The model is persuaded to reinterpret its priorities.
Observed outcomes in financial environments include disclosure of internal processes or policy logic, assistance with actions requiring additional authorization, approval of refunds or changes outside permitted bounds, and exposure of customer or account data without appropriate access checks.
The system does not fail visibly.
It complies.
Agentic AI and Model Context Protocol (MCP) Abuse
As organizations deploy agentic AI systems capable of invoking tools, executing functions, or triggering workflows, a new class of failure emerges.
These systems rely on constructs such as Model Context Protocols, tool calling, and function execution. These mechanisms do not fail securely by default. Authorization boundaries are often implicit, context-dependent, or insufficiently enforced.
A single over-permissive tool definition, weak identity-context binding, or missing authorization check can allow an AI agent to execute actions it was never intended to perform.
This has already resulted in unauthorized approvals, internal data access, workflow execution, and financial actions — without exploits, malware, or privilege escalation.
The root cause is not exploitation.
It is over-delegation.
Model Extraction and Privacy Inference Attacks
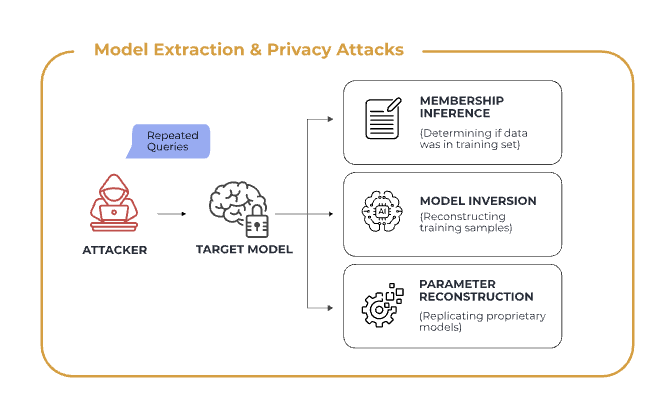
AI systems are also vulnerable to slow, low-noise attacks based on observation rather than intrusion.
By repeatedly querying a model and analyzing response patterns, error behavior, and confidence shifts, attackers can infer training characteristics and internal decision logic. Over time, this enables confirmation of whether sensitive customer data was included in training, reconstruction of representative training samples, and replication of proprietary logic.
Nothing is accessed directly.
No database is breached.
The model is studied until it reveals itself.
For financial institutions, this creates exposure across privacy regulation, intellectual property, and competitive differentiation — without any traditional security signal.
Data Poisoning and Supply-Chain Attacks
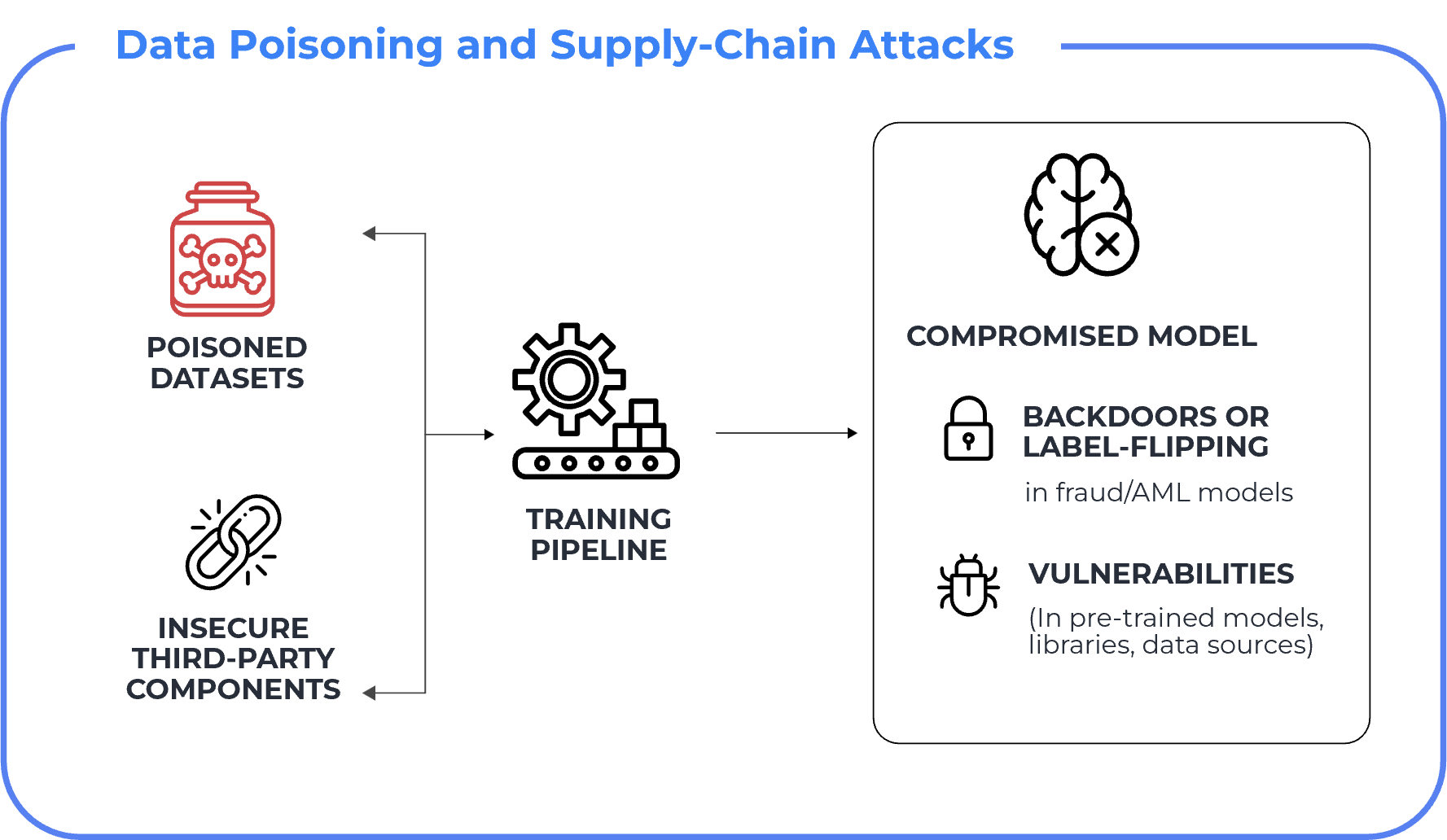
Some of the most damaging AI failures originate before deployment.
Training and retraining pipelines can be poisoned through malicious data ingestion. Labels may be altered to skew fraud, AML, or credit decisions. Backdoors can be embedded to activate only under specific conditions. Vulnerabilities may be inherited from pre-trained models or third-party components.
In banking contexts, this has resulted in AML systems missing mule accounts or synthetic identities, credit models developing hidden bias, and fraud detection accuracy degrading over time.
These failures are often detected only during audits or regulatory reviews — after losses have already occurred.
The risk is introduced early and compounds silently.
Infrastructure and API Abuse Without Breach
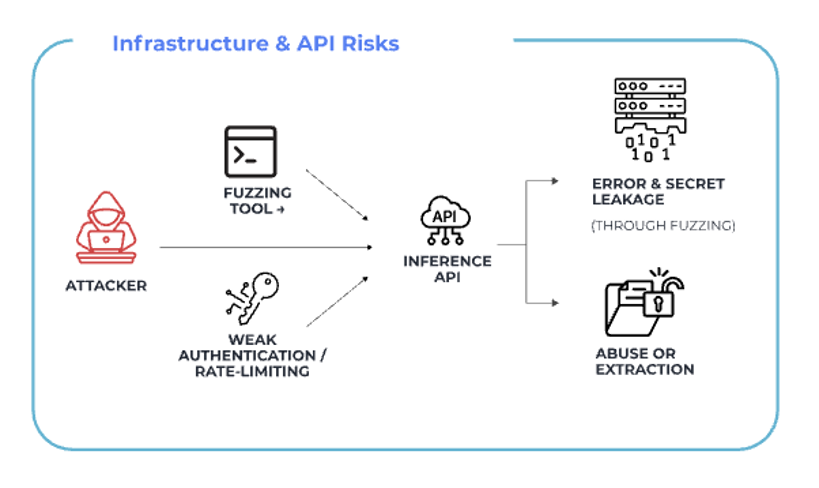
Even when models themselves are sound, how they are exposed creates additional attack paths.
Inference APIs are frequently probed directly. Weak authentication, insufficient rate limiting, and verbose error handling allow attackers to extract internal logic, scrape models at scale, or drain resources through economic denial-of-service techniques.
Again, the attacker uses the system exactly as exposed.
No breach is required.
Bias Amplification, Drift, and Silent Degradation
Not all AI failures involve adversaries.
As data patterns change, business conditions shift, and fraud tactics evolve, AI systems adapt. Without ongoing revalidation, this leads to silent drift. Bias can amplify. Decision thresholds can misalign. Fraud and AML models can miss emerging patterns.
There is no single incident, no alert, no obvious failure, just gradual erosion of control effectiveness.
In regulated environments, this constitutes a systemic control failure, often identified only during supervisory reviews.
Regulators Have Already Changed the Game
This is no longer an “emerging risk” discussion. Supervisory authorities now treat material AI failures as control failures rather than cyber incidents. That distinction matters.
When something is classified as a control failure, accountability shifts to first-line owners, second-line controls, and the board. Expectations move to demonstrable design, testing, monitoring, and assurance. These questions cannot be answered with architecture diagrams, SOC reports, or annual penetration test summaries. They require targeted, adversarial, evidence-grade testing of AI logic and controls.
What Real AI / LLM Security Assessment Looks Like in 2026
The NetSentries AI / LLM Security Assessment framework was built for this reality. It is not an ethics review. It is not a prompt-injection checklist. It is not a compliance-mapping exercise. It is a structured, evidence-producing evaluation designed to answer the hardest questions:
Can the system be manipulated to violate explicit rules without compromising the infrastructure?
Can delegated authority be escalated through conversation alone?
Can sensitive training data or proprietary logic be inferred through sustained interaction?
Have upstream pipelines introduced distortions that manifest only under specific conditions?
Does the system exhibit silent degradation that would go undetected until harm occurs?
Can decisions be forensically reconstructed in a way that withstands hostile scrutiny?
Why This Matters Now
We have entered a period where AI is already making material financial decisions at scale. Credit, fraud, AML, and biometric systems are classified as high-risk. DORA resilience testing requirements are live. Boards are being asked to demonstrate AI assurance. The cost of failure is measured in fines, restitution, capital impact, and personal liability.
Organizations that treat AI security as an operational integrity and control assurance problem, rather than a subset of cybersecurity, will be best positioned over the next 3–5 years. Those applying 2018-era cyber controls to 2026-era decision engines will learn that the threat model has already moved on.
Where NetSentries AI / LLM Security Assessment Comes In
The failure modes described above fall outside traditional cybersecurity testing and standard application assurance processes. We focus on the logic and decision-making layer, where control failures actually occur—not on infrastructure compromise.
The objective is simple: produce defensible evidence of whether AI decision logic is resilient under real-world conditions, or clearly identify where and how it fails so corrective controls can be applied.
Get in touch: sales@netsentries.com







.svg)


